Vor geraumer Zeit habe ich im Rahmen eines Vortrages eine kleine Datensammlung von DB Daten durchgeführt und diese dann nach kurzer Zeit wieder deaktiviert. Einige Zeit danach aktivierte ich die Datensammlung dann wieder und erweiterte sie noch um weitere Funktionen und Datenpunkte. Inzwischen sind so ca. 800000 Datensätze zusammengekommen, welche in einem Grafana schön lesbar dargestellt werden. Alle 30 min werden so von ca. 50 Bahnhöfen Datensätze erstellt und in einer MariaDB Datenbank persistiert.
Datenpunkte
Meine Daten kommen in diesem Fall einerseits von der API aus der man den Status von Facilities (Fahrstühle etc.) auslesen kann und andererseits von verschiedenen APIs mit denen ich Zugdaten und deren Verspätungen berechnen kann.
Das funktioniert wie folgt: Mit dem Namen des jeweiligen Bahnhofes kann man die Abfahrts-/Ankunftsfahrpläne auslesen und bekommt dadurch die IDs der jeweiligen Züge. Mit Hilfe einer weiteren API kann man nun genauere Informationen zu diesem Zug erhalten. Um eventuell irgendwann auch noch eine Karte mit POIs zu erstellen habe ich zusätzlich dazu auch noch die Geographischen Daten der Bahnhöfe in einer Datenbank gespeichert.
Datenanalyse
Mit Hilfe von Grafana stelle ich die gespeicherten Daten dann graphisch da. So kann ich z.B. die Wahrscheinlichkeit einer Verspätung je Zug-Typ und Tag berechnen und so eine Kurve erzeugen an welchen Tagen die Wahrscheinlichkeit für eine Verspätung am höchsten oder am geringsten ist.


Die Daten der verschiedenen Facitlities habe ich in ähnlicher Form dargestellt mit dem Unterschied, dass ich hier zwischen Aktiven und Inaktiven Facilities unterschieden habe. Dadurch ensteht ähnlich wie bei den Verspätungen ein Kurve welche anzeigt wie viele Facilities im jeweiligen Status waren.
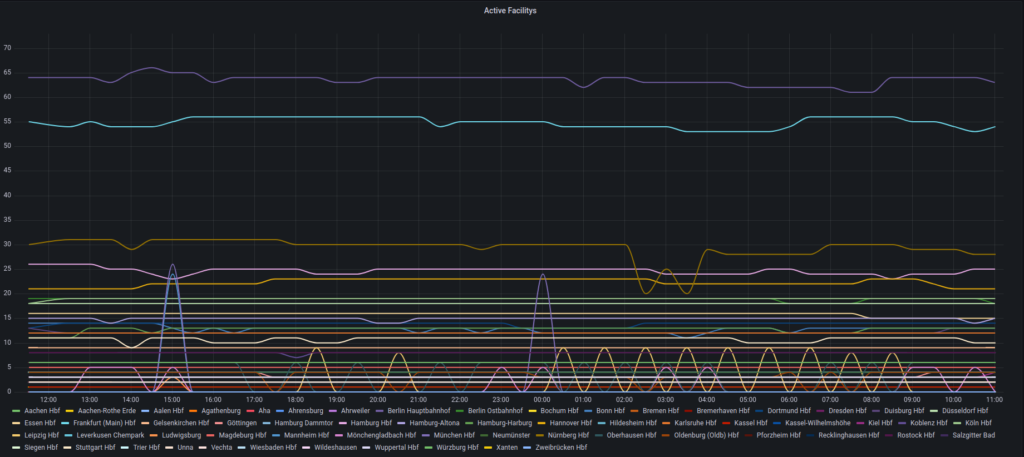
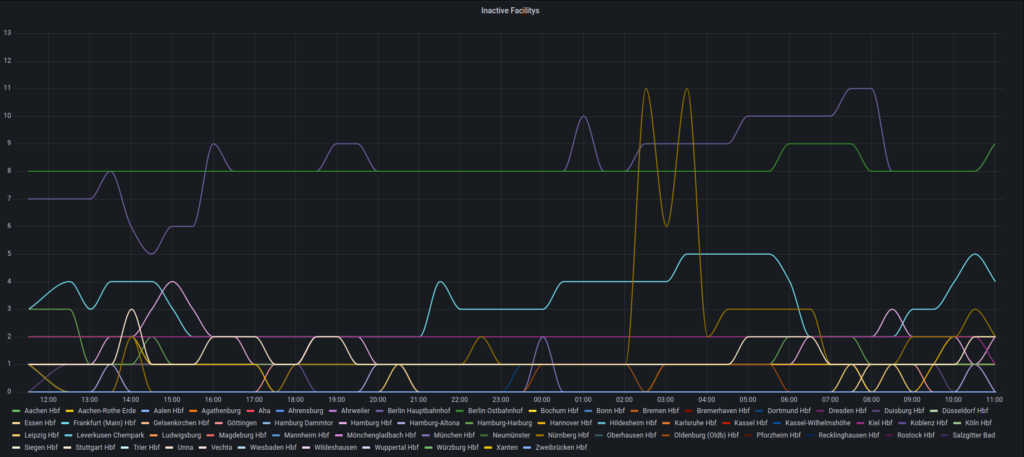
Fazit
Die Datensammlung wird langsam aussgekräftiger da ich inzwischen schon eine ordentliche Menge an Daten gesammelt habe. Leider kam es aber einige Male zu API Ausfällen auf Seiten der DB wodurch Lücken entstanden die ich auch nicht wieder beheben konnte. Auch viel die VM auf welcher ich die Datensammlung durchführe einige Male aus, was die gleichen Folgen hatte. Auch habe ich mitten in der Datensammlung die Daten auf eine neue VM umziehen müssen, da die Alte an Ihre Grenzen kam. Ich werde die Sammlung weiterlaufen lassen und eventuell auch noch einige Updates durchführen und diese dann hier ergänzen.
Ressourcen
- VM (RAM: 8 GB – DISK: 250 GB – CPU 4 Cores)
- API-Token
Quellen
Zugehöriges GIT-Repo folgt in Kürze